
存储系统基本概念
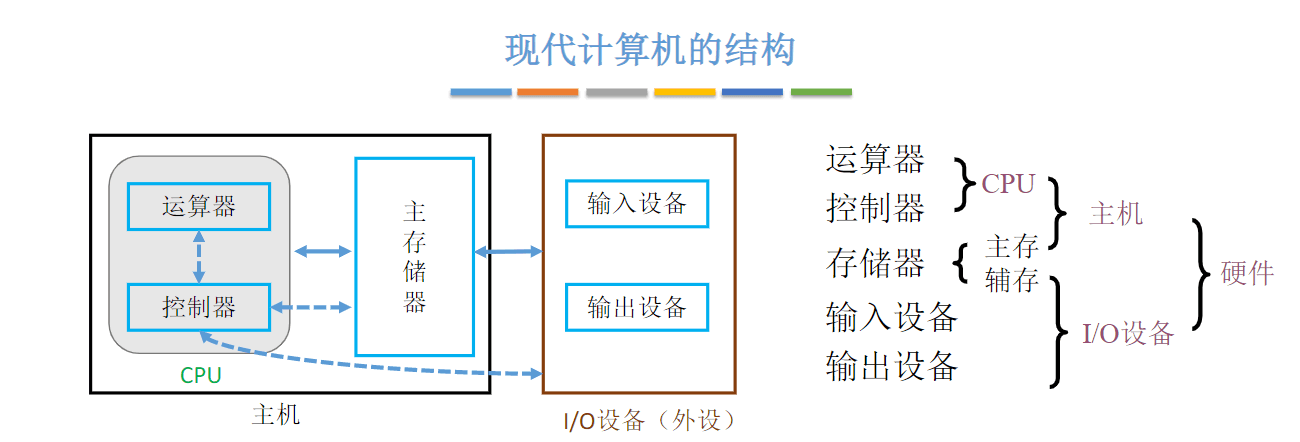 存储器的层次结构
存储器的层次结构
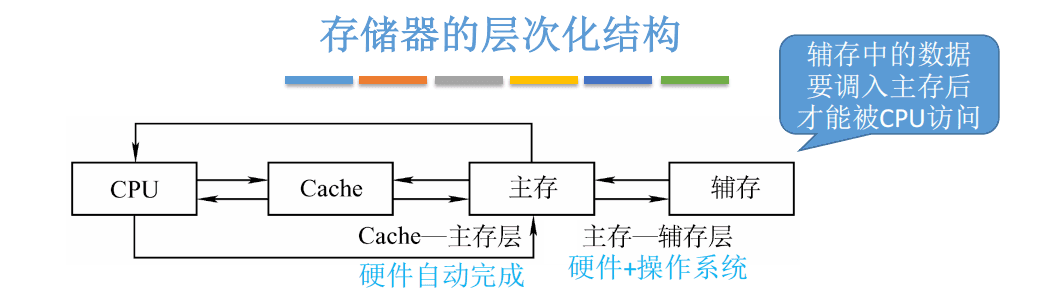 比如,运行手机app时,必须先将app的数据从辅存读入到主存。
比如,运行手机app时,必须先将app的数据从辅存读入到主存。
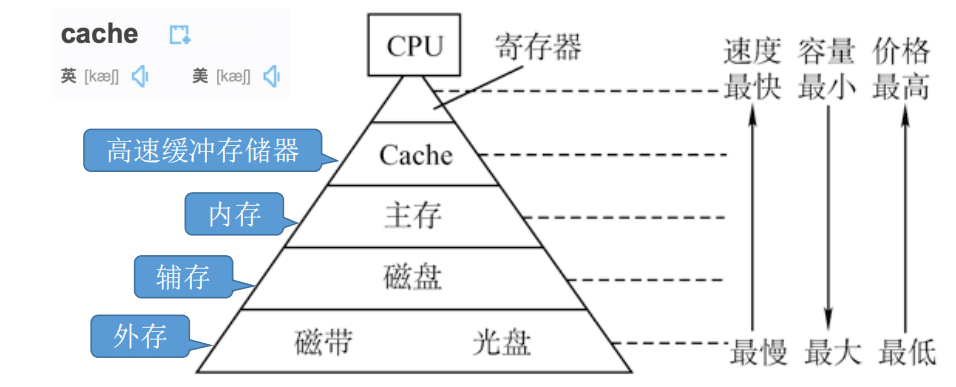 注:有的教材把安装在电脑内部的磁盘称为“辅存”,把U盘、光盘等称为“外存”。也有的教材把磁盘、U盘、光盘等统称为“辅存”或“外存
注:有的教材把安装在电脑内部的磁盘称为“辅存”,把U盘、光盘等称为“外存”。也有的教材把磁盘、U盘、光盘等统称为“辅存”或“外存
主存—辅存:实现虚拟存储系统,解决了主存容量不够的问题
Cache—主存:解决了主存与CPU速度不匹配的问题
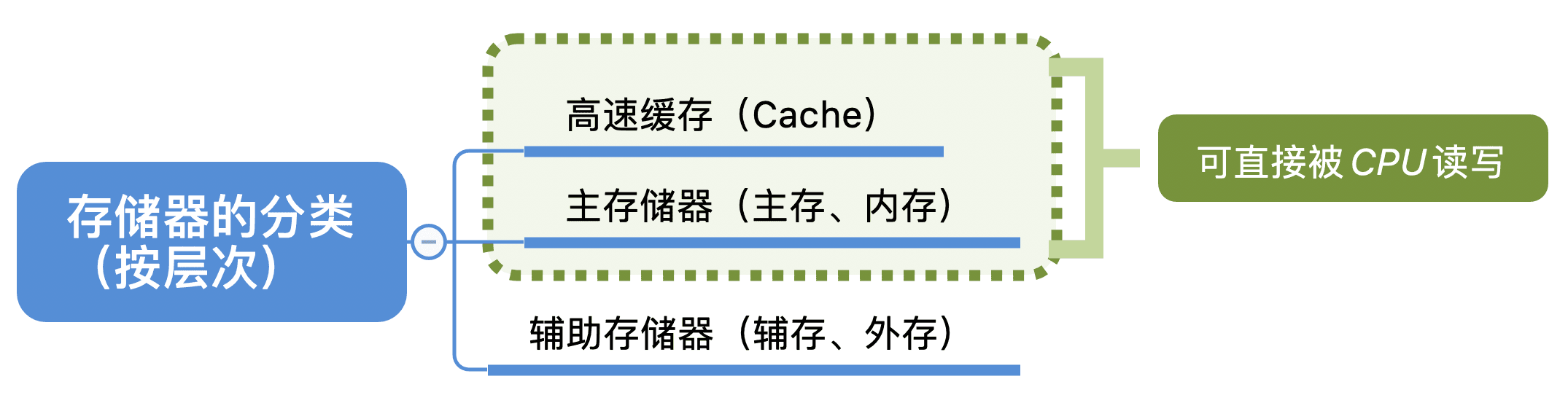
存储器的分类
-
按层次分类
-
按存储介质分类:
1. 半导体存储器(主存、Cache)
2. 磁表面存储器 磁盘、磁带
3. 光存储器 -
按存取方式分类

-
按信息的可更改性分类
1. 读写存储器(Read/Write Memory)——即可读、也可写(如:磁盘、内存、Cache)
2. 只读存储器(Read Only Memory)——只能读,不能写(如:实体音乐专辑通常采用 CD-ROM,实体电影采用蓝光光碟,BIOS通常写在ROM中) -
按信息的可保存性分类
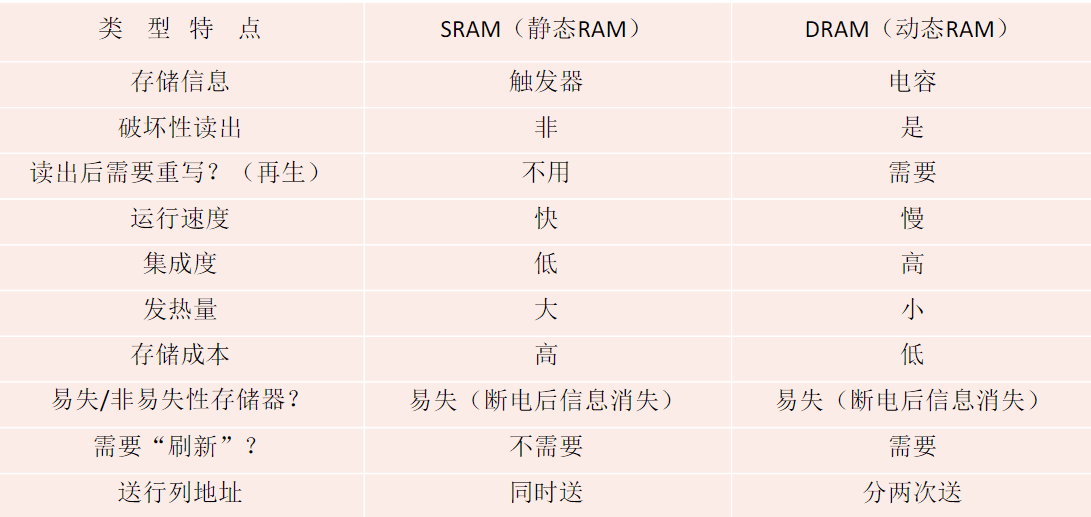
1. 断电后,存储信息消失的存储器——易失性存储器(主存、Cache)
2. 断电后,存储信息依然保持的存储器——非易失性存储器(磁盘、光盘)
3. 信息读出后,原存储信息被破坏——破坏性读出(如DRAM芯片,读出数据后要进行重写)
4. 信息读出后,原存储信息不被破坏——非破坏性读出(如SRAM芯片、磁盘、光盘)
存储器的性能指标
1. 存储容量:存储字数×字长(如1M×8位)。
MDR位数反映存储字长
2. 单位成本:每位价格=总成本/总容量。
3. 存储速度:数据传输率=数据的宽度/存储周期。
数据的宽度即存储字长
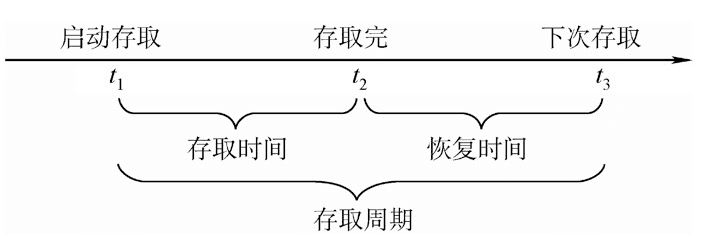 ① 存取时间(Ta):存取时间是指从启动一次存储器操作到完成该操作所经历的时间,分为读出时间和写入时间。
① 存取时间(Ta):存取时间是指从启动一次存储器操作到完成该操作所经历的时间,分为读出时间和写入时间。
② 存取周期(Tm):存取周期又称为读写周期或访问周期。它是指存储器进行一次完整的读写操作所需的全部时间,即连续两次独立地访问存储器操作(读或写操作)之间所需的最小时间间隔。
主存带宽(Bm):主存带宽又称数据传输率,表示每秒从主存进出信息的最大数量,单位为字/秒、字节/秒(B/s)或位/秒(b/s)。
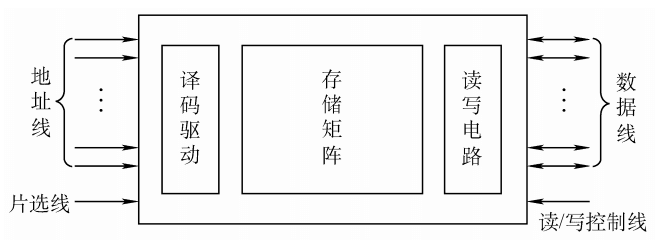
主存储器的基本组成
MOS管可理解为一种电控开关,输入电压达到某个阈值时,MOS管就可以接通
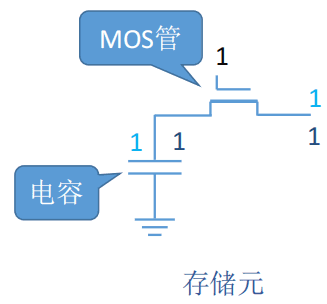 充电:写入数据;放电:读出数据
充电:写入数据;放电:读出数据
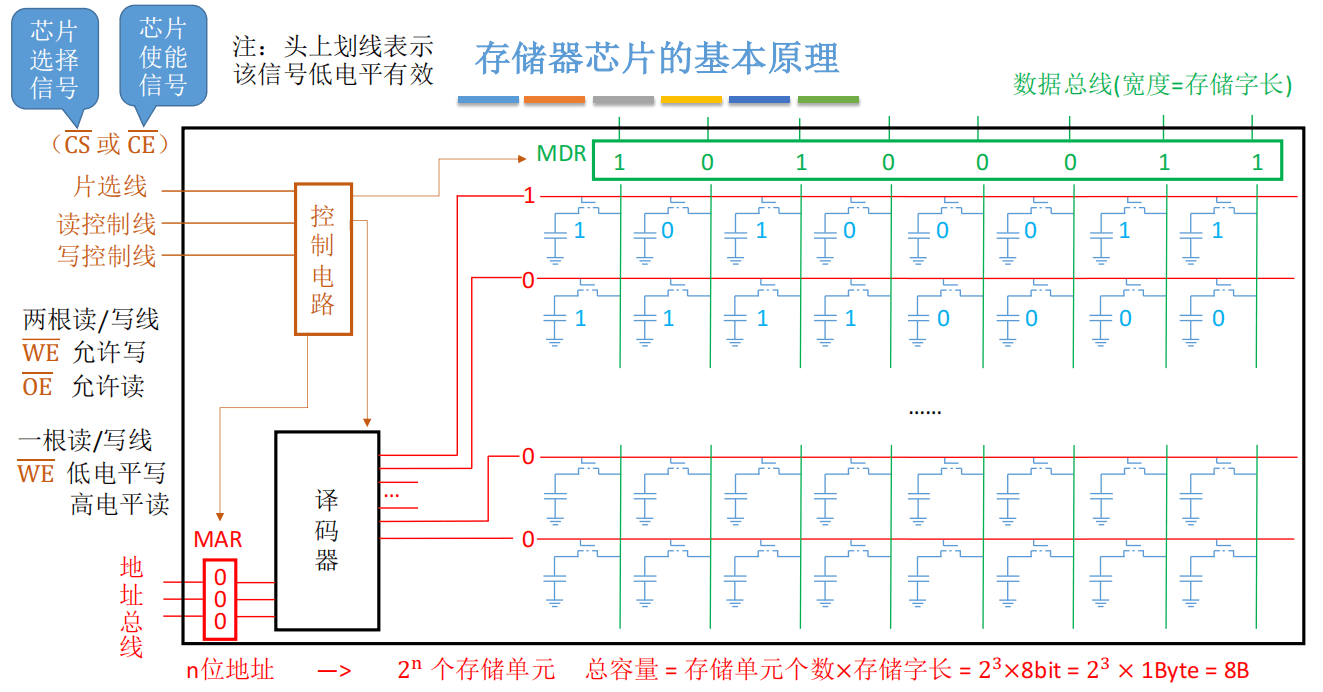 封装后的效果:
封装后的效果:
 片选线作用:选择内存条中特定的存储芯片
片选线作用:选择内存条中特定的存储芯片
SRAM和DRAM
SRAM VS DRAM
Dynamic Random Access Memory,即动态RAM
Static Random Access Memory,即静态RAM
DRAM用于主存,SRAM用于Cache
DRAM芯片:使用栅极电容存储信息
SRAM芯片:使用双稳态触发器存储信息
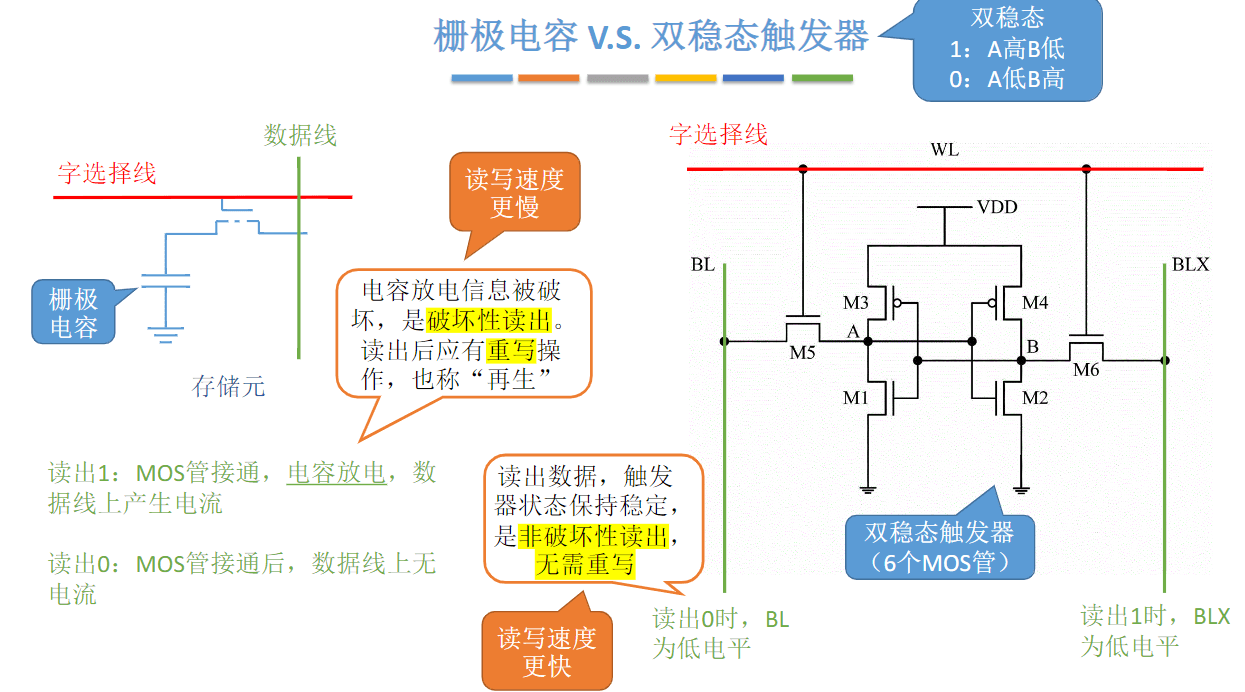 栅极电容每个存储元制造成本更低,集成度高,功耗低,每隔2ms需要刷新一次
栅极电容每个存储元制造成本更低,集成度高,功耗低,每隔2ms需要刷新一次
双稳态触发器每个存储元制造成本更高,集成度低,功耗大,只要不断电,状态就不会改变
 DRAM的刷新
DRAM的刷新
1. 多久需要刷新一次? 刷新周期:一般为2ms
2. 每次刷新多少存储单元?以行为单位,每次刷新一行存储单元
存储单元排列成2^{n/2} × 2^{n/2}的矩阵(为了减少选通线)
3. 如何刷新?有硬件支持,读出一行的信息后重新写入,占用1个读/写周期
4. 在什么时刻刷新?假设DRAM内部结构排列成128×128的形式,读/写周期0.5us,2ms共 2ms/0.5us = 4000 个周期
 行、列地址分两次送,可使地址线更少,芯片引脚更少
行、列地址分两次送,可使地址线更少,芯片引脚更少
只读存储器ROM
RAM芯片——易失性,断电后数据消失
ROM芯片——非易失性,断电后数据不会丢失
MROM(Mask Read-Only Memory)——掩模式只读存储器
厂家按照客户需求,在芯片生产过程中直接写入信息,之后任何人不可重写(只能读出)
可靠性高、灵活性差、生产周期长、只适合批量定制
PROM(Programmable Read-Only Memory)——可编程只读存储器
用户可用专门的PROM写入器写入信息,写一次之后就不可更改
EPROM(Erasable Programmable Read-Only Memory)——可擦除可编程只读存储器
允许用户写入信息,之后用某种方法擦除数据,可进行多次重写
UVEPROM(ultraviolet rays)——用紫外线照射8~20分钟,擦除所有信息
EEPROM(也常记为E2PROM,第一个E是Electrically)——可用“电擦除”的方式,擦除特定的字
 主板上的BIOS芯片(ROM),存储了“自举装入程序”,负责引导装入操作系统(开机)
主板上的BIOS芯片(ROM),存储了“自举装入程序”,负责引导装入操作系统(开机)
注:我们常说“内存条”就是“主存”,但事实上,主板上的ROM芯片也是“主存”的一部分。逻辑上,主存由
RAM+ROM组成,且二者常统一编址
双口RAM&多模块存储器
双端口RAM
作用:优化多核CPU访问一根内存条的速度
两个端口对同一主存操作有以下4种情况:
1. 两个端口同时对不同的地址单元存取数据。
2. 两个端口同时对同一地址单元读出数据。
3. 两个端口同时对同一地址单元写入数据。
4. 两个端口同时对同一地址单元,一个写入数据,另一个读出数据。
多体并行存储器
-
高位交叉编址
-
低位交叉编址
低位交叉编址效率更高
例:每个存储体存取周期为T,存取时间为r,假设 T=4r
 采用“流水线”的方式并行存取(宏观上并行,微观上串行)
采用“流水线”的方式并行存取(宏观上并行,微观上串行)
宏观上,一个存储周期内,m体交叉存储器可以提供的数据量为单个模块的m倍。
存取周期为T,存取时间为r,为了使流水线不间断,应该使模块数>=T/r
存取周期为T,总线传输周期为r,为了使流水线不间断,应该使模块数>=T/r
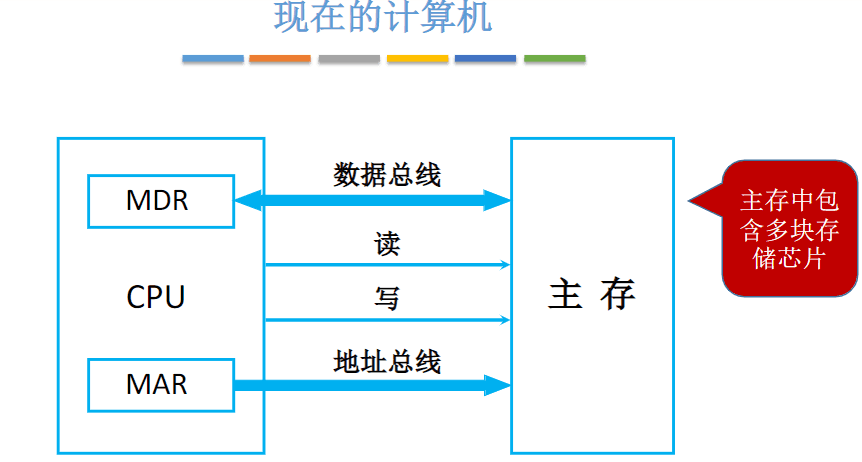
主存储器与CPU的连接
现在的计算机MAR、MDR通常集成在CPU内部。存储芯片内只需一个普通的寄存器(暂存输入、输出数据)
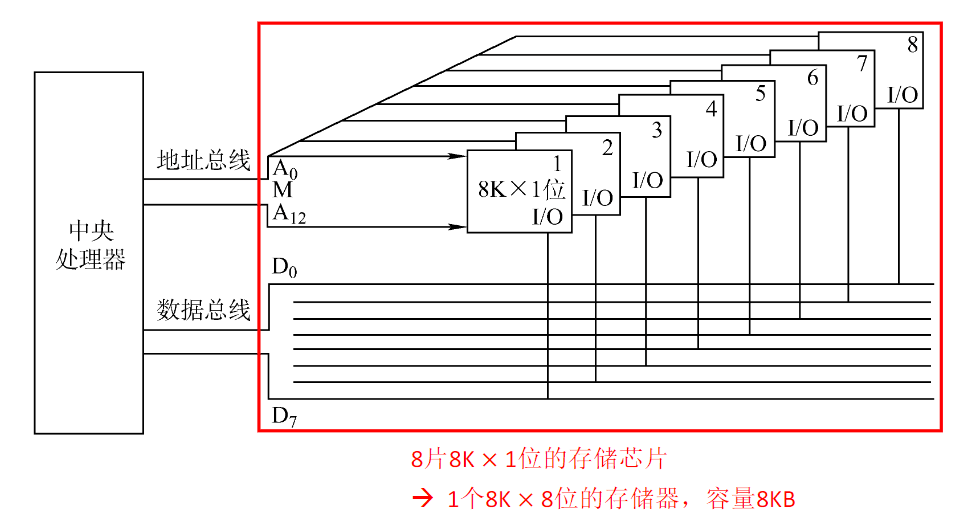
 位扩展
位扩展
 字扩展
字扩展
-
线选法:
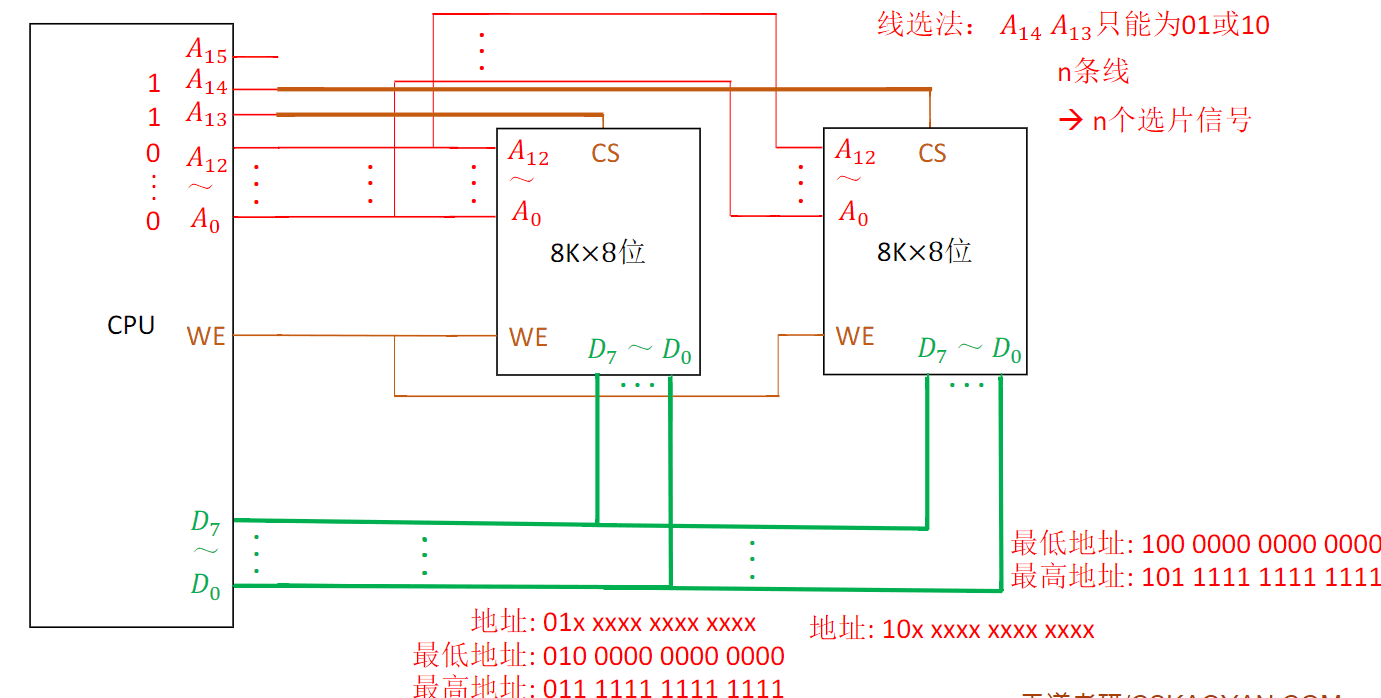
-
译码片选法:
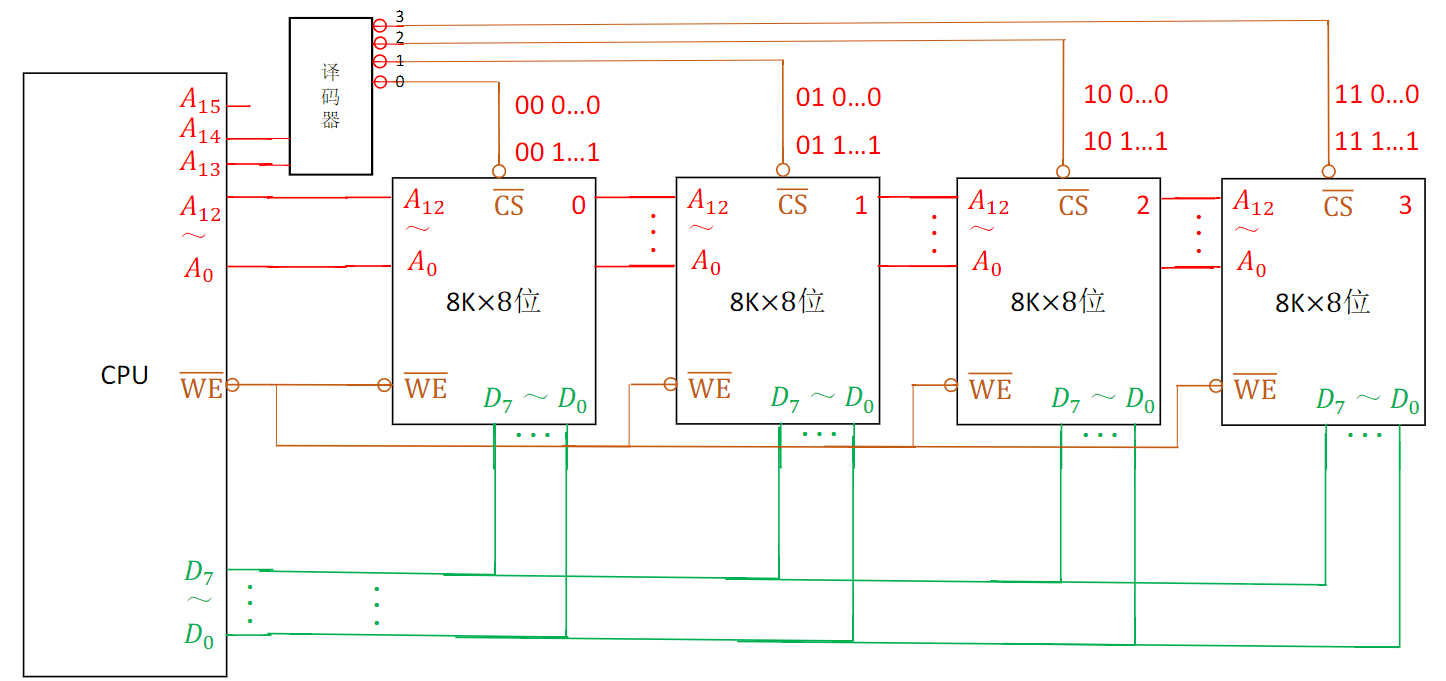
综上,我们对比线选法和译码片选法
 字位同时扩展
字位同时扩展
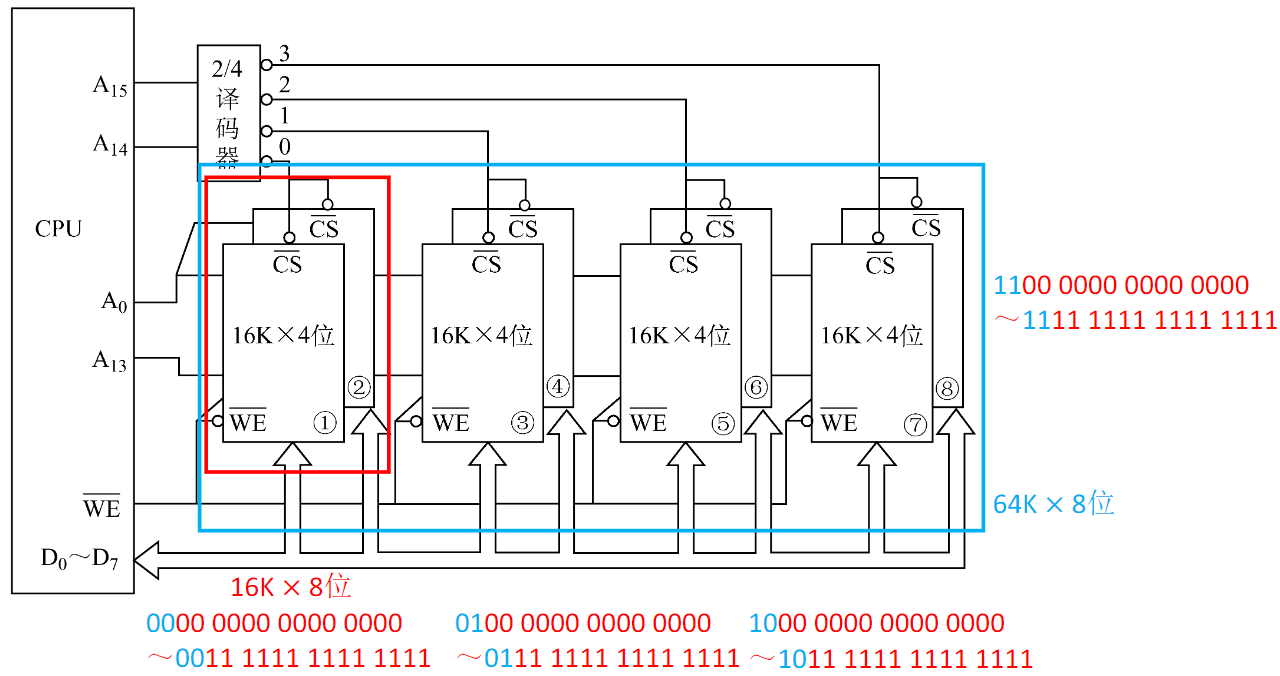
外部存储器
磁盘存储器
-
磁盘设备的组成:

-
磁盘的性能指标:

-
磁盘地址:

-
硬盘的工作过程:
硬盘的主要操作是寻址、读盘、写盘。每个操作都对应一个控制字,硬盘工作时,第一步是取控制字,第二步是执行控制字。
硬盘属于机械式部件,其读写操作是串行的,不可能在同一时刻既读又写,也不可能在同一时刻读两组数据或写两组数据。
必须加入并串变换电路
磁盘阵列
RAID( Redundant Array of Inexpensive Disks,廉价冗余磁盘阵列)是将多个独立的物理磁盘组成一个独
立的逻辑盘,数据在多个物理盘上分割交叉存储、并行访问,具有更好的存储性能、可靠性和安全性。
RAID0没有容错能力,RAID1容量减少一半。
固态硬盘SSD
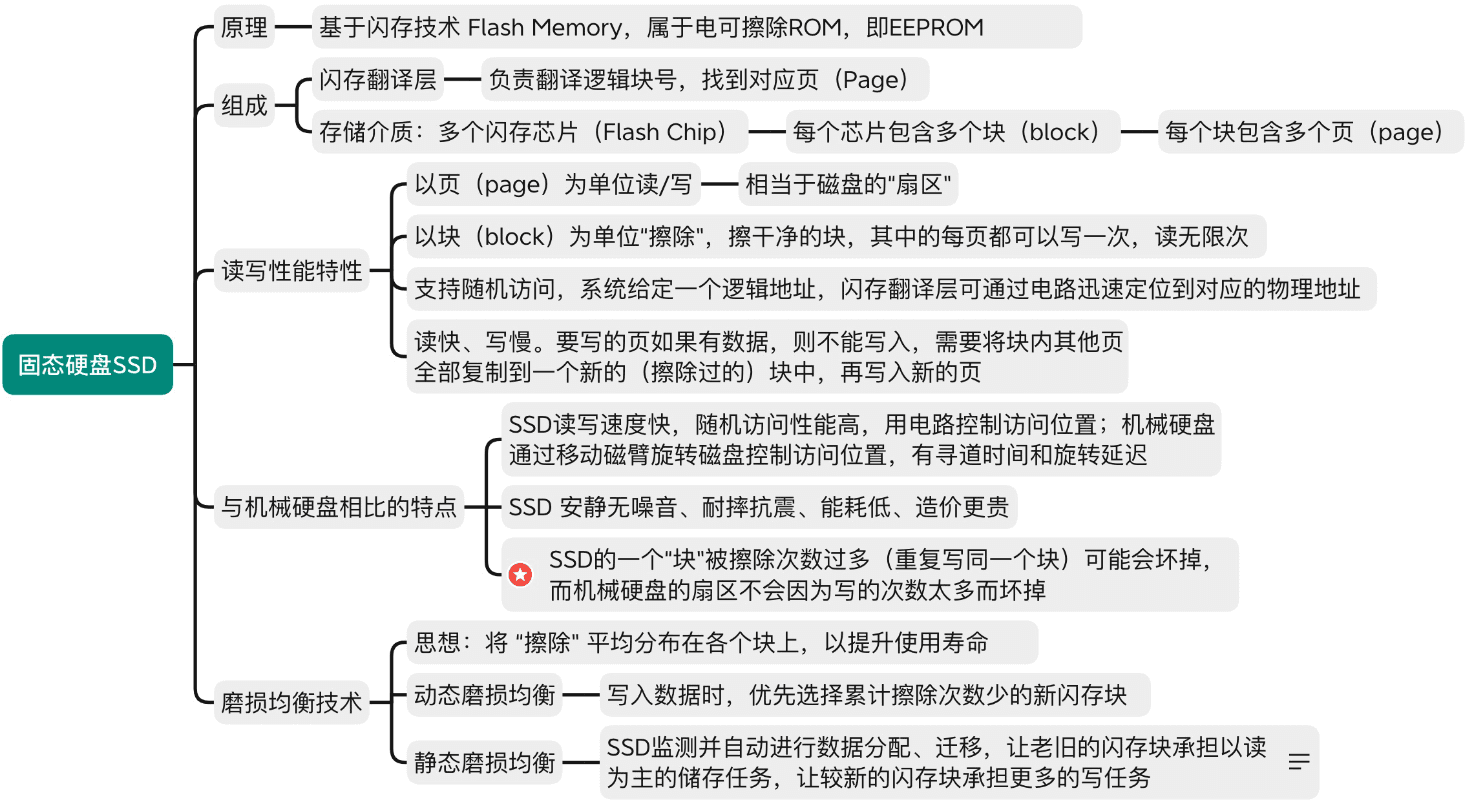
高速缓冲存储器
Cache工作原理
实际上,Cache 被集成在CPU内部
Cache用SRAM实现,速度快,成本高
局部性原理
-
空间局部性:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是临近的
-
时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息
根据局部性原理,可以把CPU目前访问的地址“周围”的部分数据放到Cache中
性能分析

例:设Cache的速度是主存的5倍,且Cache的命中率为95%,则采用Cache后,
存储器性能提高多少(设Cache和主存同时被访问,若Cache命中则中断访问主存)?
 Q:基于局部性原理,不难想到,可以把CPU目前访问的地址“周围”的部分数据放到Cache中。如何界定“周围”?
Q:基于局部性原理,不难想到,可以把CPU目前访问的地址“周围”的部分数据放到Cache中。如何界定“周围”?
A:将主存的 存储空间“分块”,如:每 1KB 为 一块。主存与Cache之间以“块”为单位进行数据交换
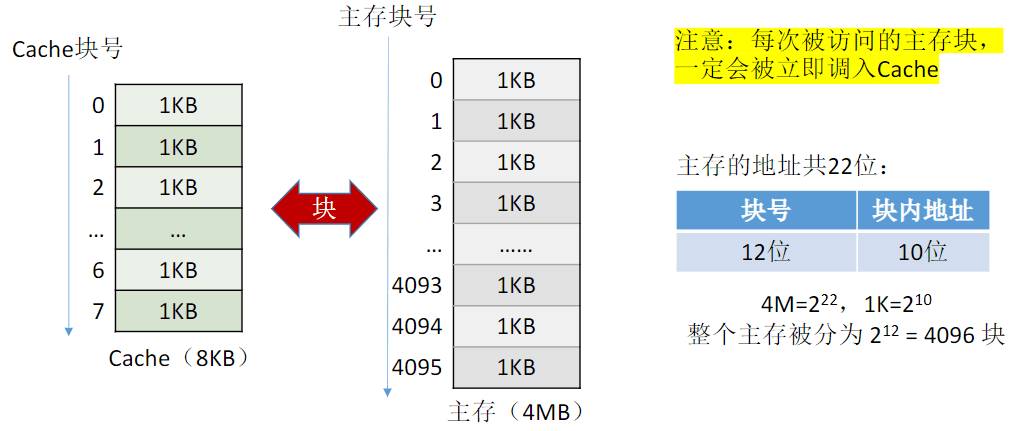
-
如何区分 Cache 与 主存 的数据块对应关系? ——Cache和主存的映射方式
-
Cache 很小,主存很大。如果Cache满了怎么办? ——替换算法
-
CPU修改了Cache中的数据副本,如何确保主存中数据母本的一致性? ——Cache写策略
Cache-主存映射方式
-
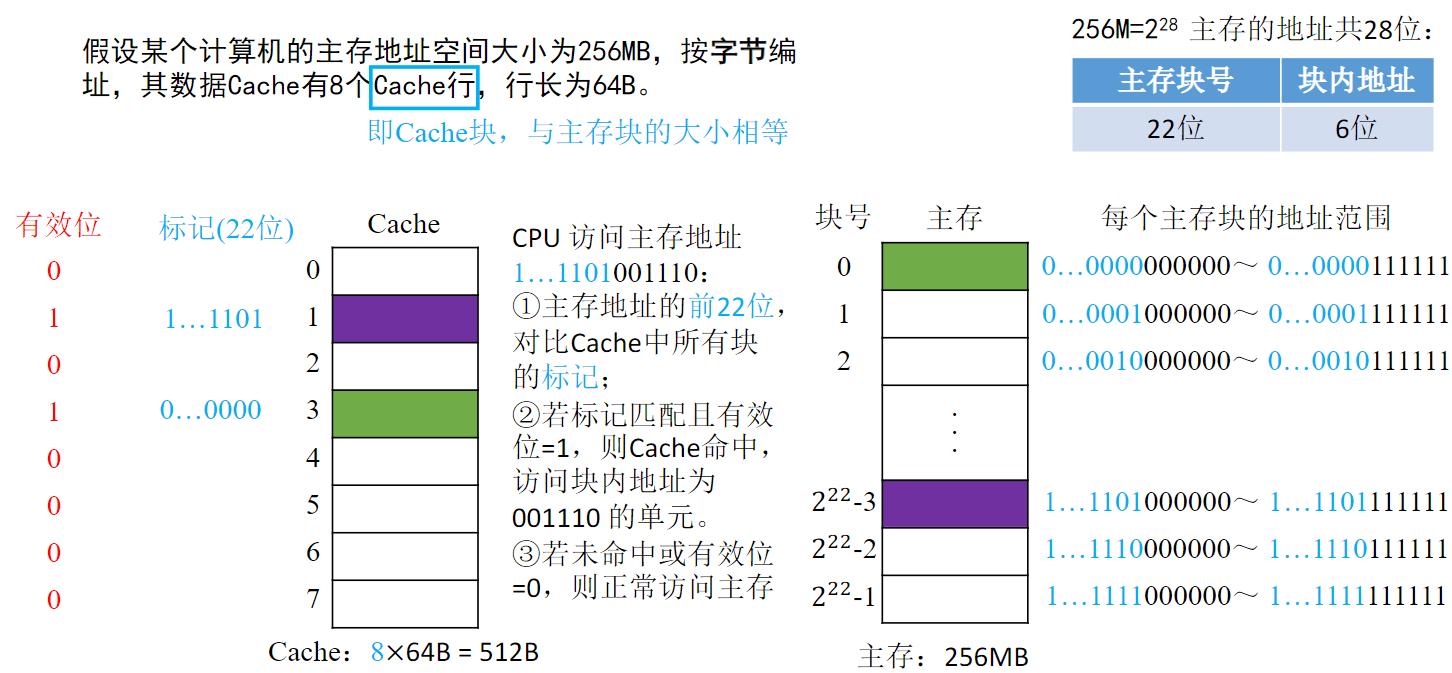
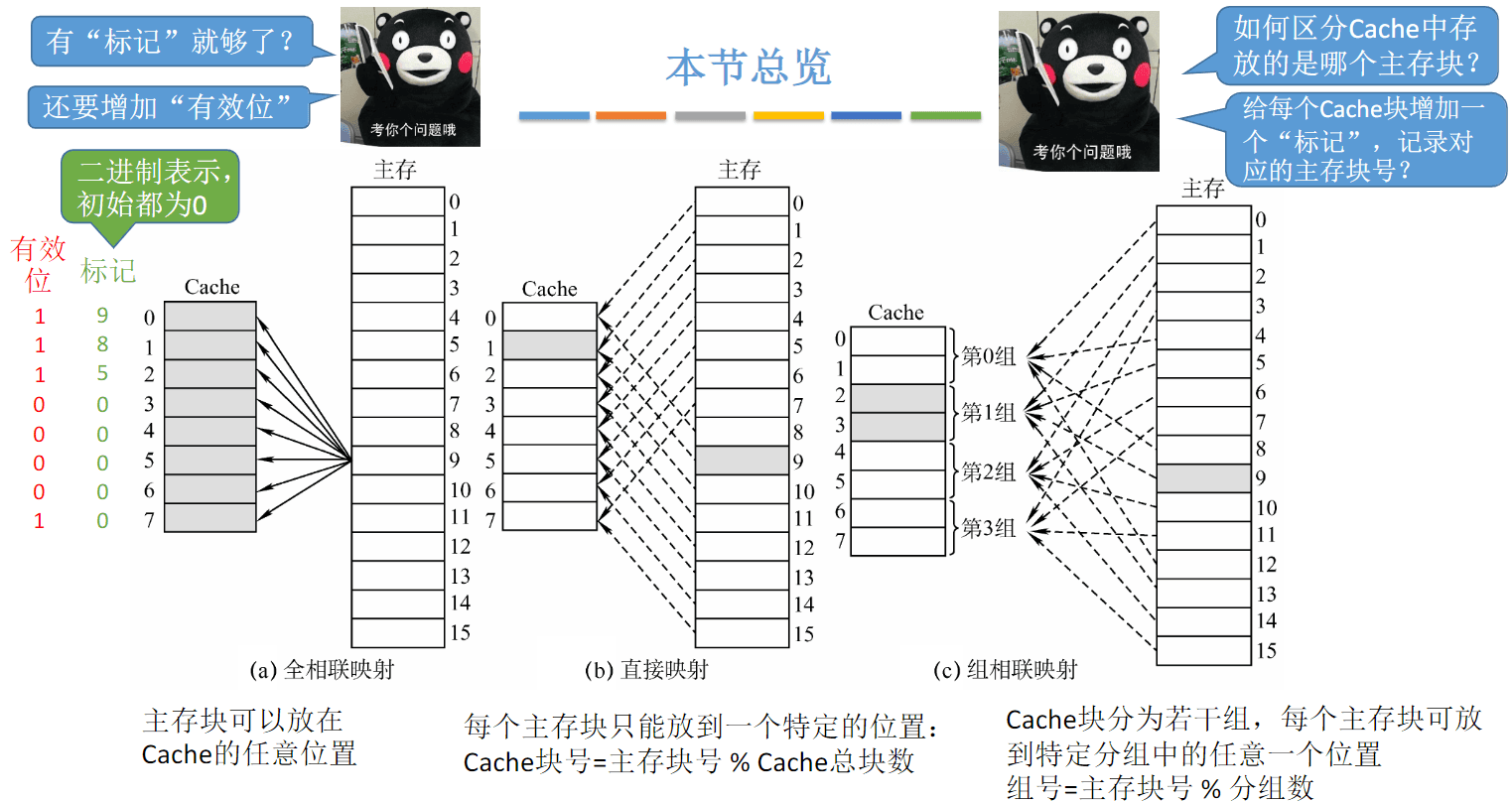 全相联映射(随意放)
全相联映射(随意放)
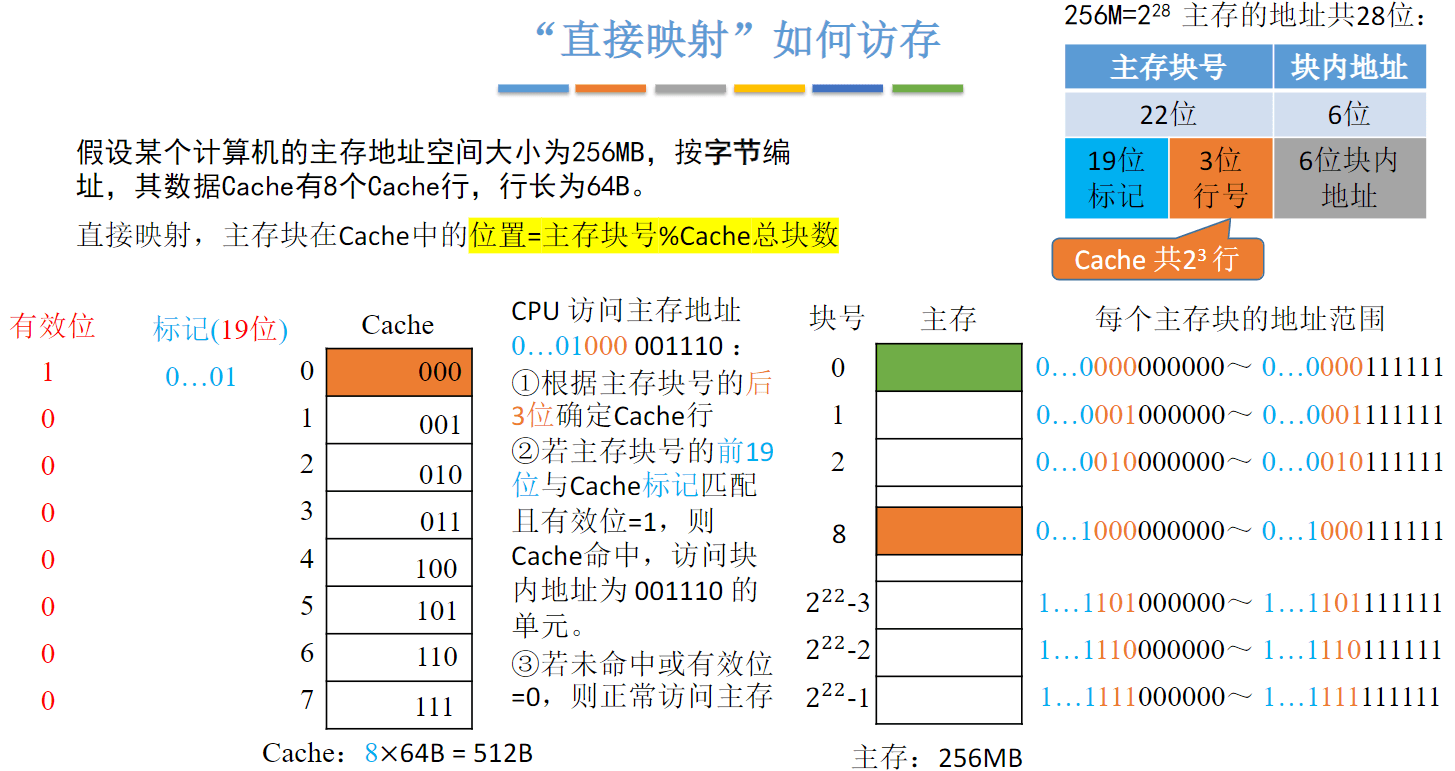
-
直接映射(只能放固定位置)
-
组相联映射(可放到特定分组)
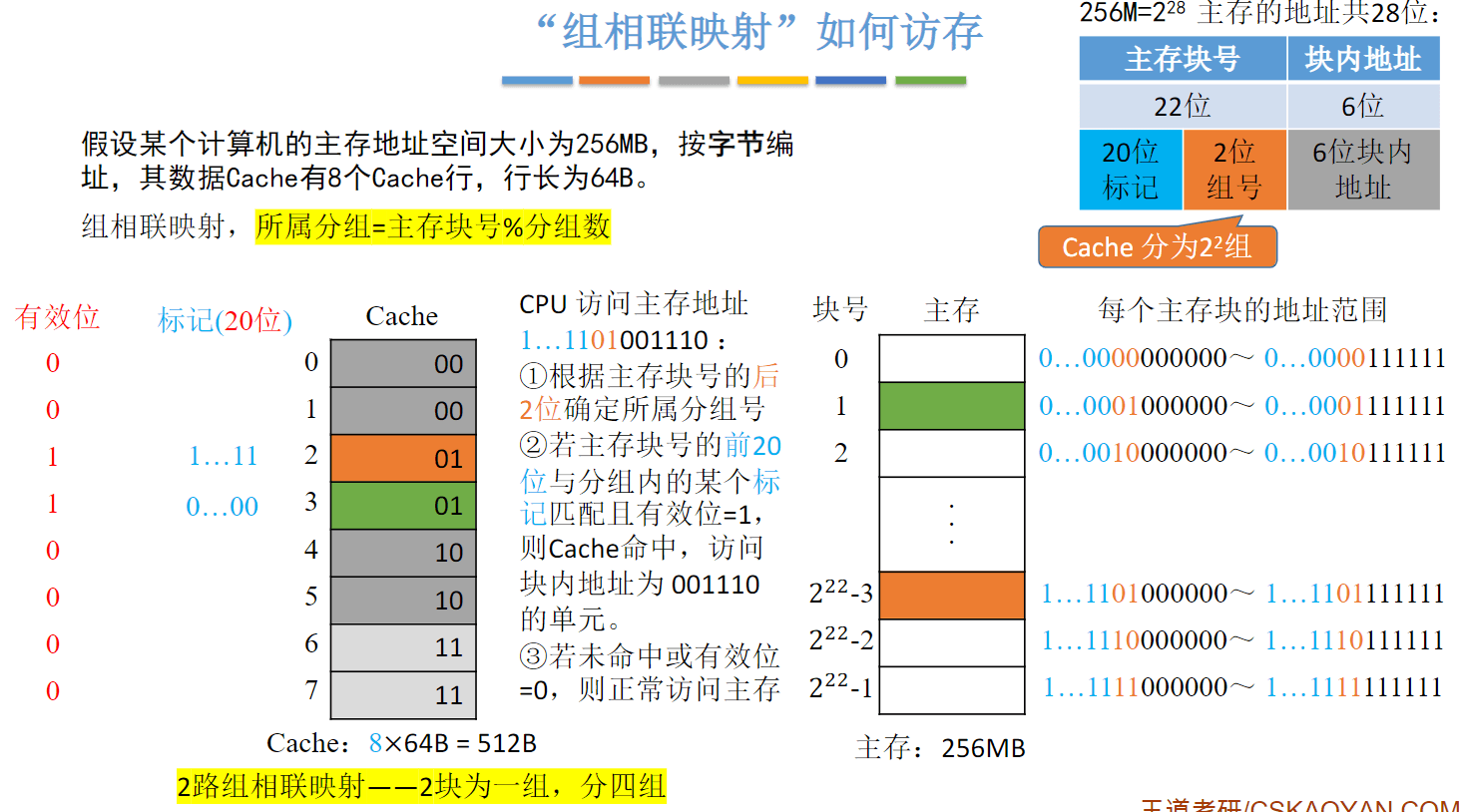
Cache替换算法
全相联映射:Cache完全满了才需要替换需要在全局选择替换哪一块
直接映射:如果对应位置非空,则毫无选择地直接替换
组相联映射:分组内满了才需要替换需要在分组内选择替换哪一块
-
随机算法(RAND):若Cache已满,则随机选择一块替换。
实现简单,但完全没考虑局部性原理,命中率低,实际效果很不稳定 -
先进先出算法(FIFO):若Cache已满,则替换最先被调入Cache 的块
实现简单,最开始按#0#1#2#3放入Cache,之后轮流替换 #0#1#2#3
FIFO依然没考虑局部性原理,最先被调入Cache的块也有可能是被频繁访
抖动现象:频繁的换入换出现象(刚被替换的块很快又被调入) -
近期最少使用算法(LRU):为每一个Cache块设置一个“计数器”,用于记录每个Cache块已经有多久没被访问了。当Cache满后替换“计数器”最大的
计数器设置:
①命中时,所命中的行的计数器清零,比其低的计数器加1,其余不变;(Cache块的总数=2^n,则计数器只需n位。)
②未命中且还有空闲行时,新装入的行的计数器置0,其余非空闲行全加1;
③未命中且无空闲行时,计数值最大的行的信息块被淘汰,新装行的块的计数器置0,其余全加1。
基于“局部性原理”,近期被访问过的主存块,在不久的将来也很有可能被再次访问,因
此淘汰最久没被访问过的块是合理的。LRU算法的实际运行效果优秀,Cache命中率高。
若被频繁访问的主存块数量 > Cache行的数量,则有可能发生“抖动”,如:{1,2,3,4,5,1,2,3,4,5,1,2...} -
最不经常使用算法(LFU):为每一个Cache块设置一个“计数器”,用于记录每个Cache块被访问过几次。当Cache满后替换“计数器”最小的
曾经被经常访问的主存块在未来不一定会用到(如:微信视频聊天相关的块),,并没有很好地遵循局部性原理,因此实际运行效果不如 LRU
近期最少使用算法(LRU)最优秀
Cache写策略
-
写命中
写回法(write-back) —— 当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存。(减少了访存次数,但存在数据不一致的隐患)
全写法(写直通法,write-through) —— 当CPU对Cache写命中时,必须把数据同时写入Cache和主存,一般使用写缓冲(write buffer)。(访存次数增加,速度变慢,但更能保证数据一致性)
注:使用写缓冲,CPU写的速度很快,若写操作不频繁,则效果很好。若写操作很频繁,可能会因为写缓冲饱和而发生阻塞 -
写不命中
写分配法(write-allocate)——当CPU对Cache写不命中时,把主存中的块调入Cache,在Cache中修改。通常搭配写回法使用。
非写分配法(not-write-allocate)——当CPU对Cache写不命中时只写入主存,不调入Cache。搭配全写法使用。